April 21, 2014
## Preface This article is the first of four in a series, in which I argue that thinking of a memory access as _O(1)_ is generally a bad idea, and we should instead think of them as taking _O(√N)_ time. In part one I lay out a hand-wavy argument based on a benchmark. In [part II](2014_04_28_myth_of_ram_2.html) I build up a mathematical argument based in theoretical physics, and in [part III](2014_04_29_myth_of_ram_3.html) I investigate some implications. [Part IV](2015_02_09_myth_of_ram_4.html) is a FAQ in which I answers some common questions and misunderstandings. (This preface was added on August 29, 2016) ## Intro If you have studied computing science, then you know how to do [complexity analysis](https://en.wikipedia.org/wiki/Analysis_of_algorithms#Run-time_analysis). You'll know that the time complexity for iterating through a linked list is _O(N)_, binary search is _O(log(N))_ and a hash table lookup is _O(1)_. What if I told you that all of the above is not just misleading, but wrong? What if I told you that the time it takes to iterate through a linked list is actually _O(N√N)_ and hash lookups are _O(√N)_? Don't believe me? By the end of this series of articles you will. I will show you that accessing memory is not a _O(1)_ operation but _O(√N)_. This is a result that holds up both in theory and practice. Let’s start with the latter: ## Measuring it First of all, let's get our definitions straight. [Big O notation](https://en.wikipedia.org/wiki/Big_O_notation) can be applied to many things, from memory usage to instructions executed. For the purpose of this series of articles I'll be using the _O(f(N))_ to mean that _f(N)_ is an upper bound (worst case) of the *time* it takes to accomplish a task accessing _N_ bytes of memory (or, equivalently, _N_ number of equally sized elements). That I use Big O to analyze _time_ and not _operations_ is important. As we'll see, the CPU spends a lot of time waiting for memory. Personally, I do not care what the CPU does while I wait for it – I only care about how long something takes, hence the definition above. Another clarification: the "RAM" in the title is meant to refer to random memory accesses in general, not to a specific type of memory. In this installment I measure the time it takes to access a piece of memory be it in cache, in DRAM, or in swap. In Part II I will extend this even further – but I'm getting ahead of myself. [Here’s a simple program](https://github.com/emilk/ram_bench) that iterates through a linked list of length _N_, ranging from 64 elements up to about 420 million elements. Each node consists of a 64 bit pointer and 64 bits of dummy data. The nodes of the linked list are jumbled around in memory so that each memory access is random. I measure iterating through the same list a few times, and then plot the time taken per element. This means that we should get a flat plot if random memory access is _O(1)_. This is what we actually get: 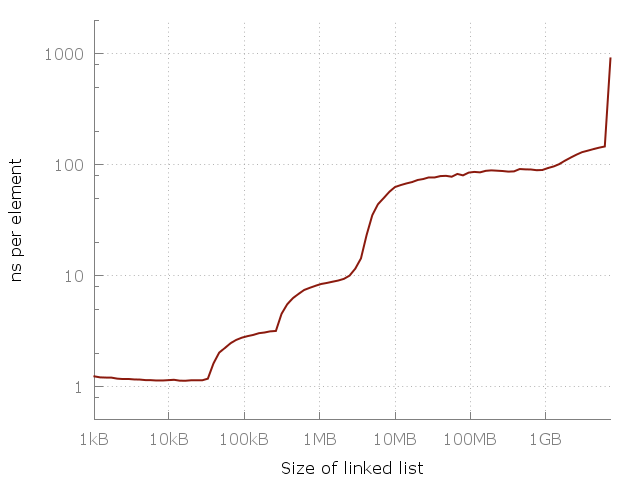 Note that this is a log-log graph, so the differences are actually pretty huge. We go from about one nanosecond per element all they way up to a microsecond! But why? The answer, of course, is caching. The system memory (RAM) is actually pretty slow and far away and so to compensate the clever computer designers have added a hierarchy of faster, closer and more expensive caches to speed things up. My computer has three levels called L1, L2, L3 of 32 kiB, 256 kiB and 4 MiB each. I have 8 GiB of RAM, but when I ran my experiment I only had about 6 GiB free – so in the last runs there was some swapping to disk (an SSD). Here’s the same plot again but with my RAM and cache sizes added as vertical lines: 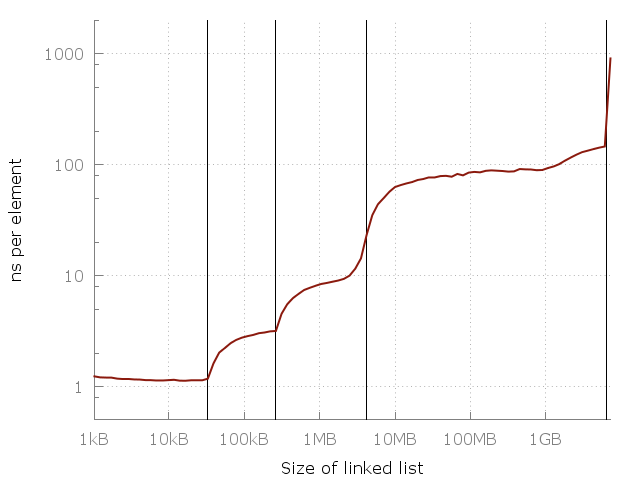 This graph should really drive home the importance of cache:s – each cache is many times faster than the previous one. This is the reality of modern CPU architectures, be it on smartphones, laptops or mainframes. But what is the pattern? Can we fit some simple equation to the plot? It turns out we can! If you look at the plot you'll see that between 10kB and 1MB there is a roughly a 10x slowdown. Between 1 MB and 100 MB there is another 10x slowdown – and again between 100 MB and 10 GB! It seems like that for each 100-fold increase in memory usage we get a 10-fold slow-down. Let's superimpose that on the graph: 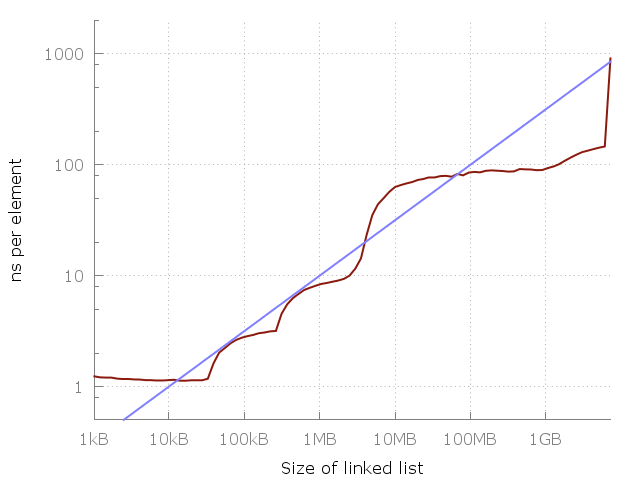 The blue line corresponds to a _O(√N)_ cost of each memory access. Seems like a pretty good fit, no? Of course this is on my machine, and it may look quite different on yours. Still, the equation is very simple to remember, so maybe we could use it as a rule of thumb. You may now wonder what will happen once we hit the right side of the graph. Will it keep climbing, or plateauing? Well, it would plateau for a while until we could no longer fit the memory on SSD and would need to go to HDD, then a disk server, then a data-center far away etc. Each such jump would create a new plateau, but the upwards trend of the latency, I will argue, would continue. The reason I did not run my experiment further is simply lack of time and lack of access to a big data-center. "But", I hear you say, "empiricism is no way to establish a Big-O bound!". It certainly isn't! Could there perhaps be a theoretical limit to the latency of a memory access? The plot thickens in [The Myth of RAM, part II](2014_04_28_myth_of_ram_2.html). !!! Note Read the discussion of the Myth of RAM series on [Reddit](https://www.reddit.com/r/programming/comments/2v8dty/the_myth_of_ram_part_i_why_a_random_memory_read/) and [Hacker News](https://news.ycombinator.com/item?id=12383012).